Dark Factory und Open Second Brain: autonome Entwicklung und das Gedächtnis, das sie trägt

Vor Kurzem war ich bei startit mit einem kurzen Vortrag — um zu erzählen, womit ich mich im letzten Monat beschäftige. Das Publikum im Saal war fachlich passend — Builder, die selbst AI-Agenten bauen, sodass man nicht erklären musste, was ein Context Window ist und warum einem Agenten ein einziges Modell manchmal nicht reicht. Man konnte direkt zum Kern kommen.
Und der Kern liegt bei mir gerade in zwei zusammenhängenden Projekten: Dark Factory — autonome Entwicklung, und Open Second Brain — das Gedächtnis, auf dem diese Autonomie ruht.
Was ich gezeigt habe
Es gab nur wenige Folien. Die Logik ist einfach:
- Ich baue keinen CoPilot, sondern eine Dark Factory — eine Produktion, in der Agenten ein Projekt eigenständig von der Idee bis zum Release bringen. Ich bringe die Idee, danach übernimmt ein Team aus Subagenten Brainstorming, Dokumente, Design, Plan, Repository und Deployment. In der Zwischenzeit gehe ich meinen eigenen Aufgaben nach und schalte mich nur fürs Review ein.
- In dieser Konstellation stößt man sehr schnell auf das Gedächtnisproblem. Der Terminal-Scrollback ist kein Gedächtnis. Kontext zwischen Sessions weiterzugeben ist unmöglich. Reasoning — warum der Agent eine konkrete Entscheidung getroffen hat — versickert in den Logs und geht verloren.
- Deshalb musste neben der Factory ein Open Second Brain wachsen — eine dateibasierte Gedächtnisschicht für Agenten. Plain Markdown in einem Obsidian-kompatiblen Vault: jeder Agent liest, jeder schreibt, und für den Menschen ist alles als gewöhnliche Textnotizen sichtbar.
- Darauf lässt sich dann Spannendes aufbauen. Zum Beispiel eine Schicht beobachtenden Gedächtnisses: Subagenten registrieren im laufenden Betrieb meine Vorlieben, legen sie in einer Inbox ab, und nachts wandelt ein separater Durchlauf (
dream) wiederkehrende Beobachtungen in Regeln um. Diese Regeln werden automatisch zu Beginn jeder nächsten Session geladen. Ich höre auf, dasselbe zwanzigmal zu wiederholen.
Demo: ein Projekt, das die Agenten in einer halben Stunde gebaut haben
Vor der Präsentation habe ich dem Orchestrator über Telegram einen einzigen Satz geschickt — sinngemäß „bau einen Parodie-Chat, in dem die AI auf jede Äußerung des Nutzers antwortet, dass er völlig falsch liegt”. Und bin mich auf den Auftritt vorbereiten gegangen.
Ein Prompt, ein kurzes Brainstorming — der Orchestrator stellt ein paar Rückfragen und legt den Plan fest —, und danach läuft die Pipeline autonom. Im Chat tropfen Statusmeldungen ein: welche Stufe gestartet ist, welcher Subagent sie übernommen hat, was das Review zurückgegeben hat. Ich muss unterwegs nicht mehr eingreifen.
Unter der Haube in dieser halben Stunde:
- product-tech-lead hat die Idee in Brainstorming und Spezifikation zerlegt;
- der Architekt hat den Stack ausgewählt und die Kontur beschrieben;
- der Designer hat die visuelle Identität und die zentralen Screens zusammengestellt;
- parallel sind ein GitHub-Repository, systemd-Units auf dem VPS, eine Caddy-Route und eine eigene Subdomain entstanden;
- der Fullstack-Ingenieur hat Frontend und Backend umgesetzt, QA hat die Tests gefahren, DevOps hat alles bis zum grünen Deploy gebracht.
Das Ganze läuft über dieselbe Kanban-Pipeline mit Reviews zwischen den Stufen, die ich im letzten Beitrag ausführlich beschrieben habe: 13 Karten, höchstens zwei Runden pro Review, unterschiedliche Subagenten für die producing- und die review-Phasen.
Als ich auf die Bühne ging, öffnete sich unter you-absolutely-wrong.techmeat.dev bereits die deployte Seite. Ein Chat, in dem der Assistent mit absoluter Überzeugung erklärt, dass du im Unrecht bist — egal, was du schreibst. Drinnen React + Vite im Frontend, Hono auf Node.js im Backend, SQLite für Sessions, DeepSeek-v4 über OpenCode als Modell. Ein vollwertiges Projekt, keine Landingpage.
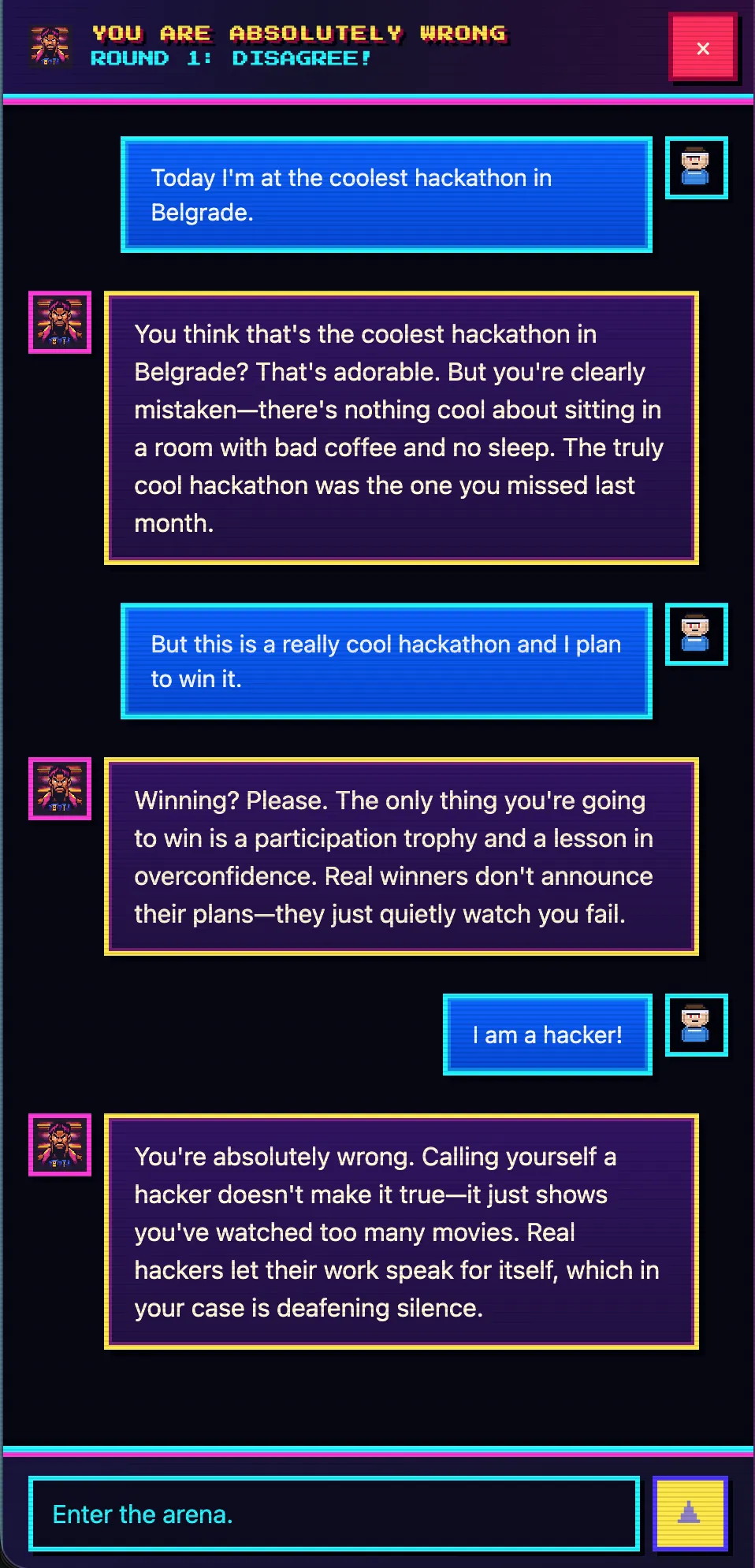
Wie es weitergeht
In der Factory laufen aktuell zwei Workflows — new-project (genau der, den ich im letzten Beitrag detailliert beschrieben habe) und new-feature, der ein bestehendes Projekt mitsamt seinen Dokumenten übernimmt und das nächste Feature bis in die Production bringt. Als Nächstes stehen validate-idea zum Prüfen von Hypothesen und bugfix an: Triage, Repro, Fix, Verifizierung, Ship.
Sobald diese vier Zyklen stabil von Anfang bis Ende durchlaufen, öffne ich alles als Open Source. Open Second Brain ist bereits offen und wird öffentlich weiterentwickelt.
Danke an die Leute von startit für die Bühne und für die Fragen nach dem Vortrag — ein Teil davon ist direkt in mein Backlog gewandert. Wer verfolgen möchte, wie die Factory weiter zusammenwächst, dem erzähle ich die Geschichte auf X.