Dark Factory et Open Second Brain : développement autonome et la mémoire qui le soutient

L’autre jour, je suis passé à startit pour une courte présentation - pour raconter ce que je fais depuis un mois. Le public dans la salle était spécialisé - des builders qui construisent eux-mêmes des agents IA, donc pas besoin d’expliquer ce qu’est une context window ni pourquoi une seule modèle ne suffit parfois pas à un agent. On pouvait passer directement à l’essentiel.
Et l’essentiel, en ce moment, ce sont deux projets liés : Dark Factory - le développement autonome, et Open Second Brain - la mémoire sur laquelle cette autonomie repose.
Ce que je montrais
Il y avait peu de slides. La logique est simple :
- Je ne construis pas un CoPilot, mais une Dark Factory - une production où les agents mènent eux-mêmes le projet de l’idée à la release. J’apporte une idée, ensuite une équipe de sous-agents fait le brainstorming, les documents, le design, le plan, le dépôt, le déploiement. Pendant ce temps, je m’occupe de mes affaires et je n’interviens que pour les revues.
- Avec cette approche, on se heurte très vite au problème de la mémoire. Le scrollback du terminal n’est pas une mémoire. Transmettre du contexte entre les sessions est impossible. Le reasoning - pourquoi l’agent a pris telle décision précise - s’échappe dans les logs et se perd.
- C’est pour cela qu’à côté de la fabrique, il a fallu faire grandir Open Second Brain - une couche de mémoire fichier pour les agents. Du Markdown brut dans un vault compatible Obsidian : n’importe quel agent lit, n’importe quel agent écrit, tout est visible par l’humain sous forme de notes texte ordinaires.
- Ensuite, on peut commencer à construire des choses intéressantes. Par exemple, une couche de mémoire observationnelle : les sous-agents repèrent mes préférences au fil du travail, les déposent dans une inbox, et la nuit une passe dédiée (
dream) transforme les observations récurrentes en règles, qui sont automatiquement chargées au début de chaque session suivante. Je cesse de répéter la même chose vingt fois.
Démonstration : un projet assemblé par des agents en une demi-heure
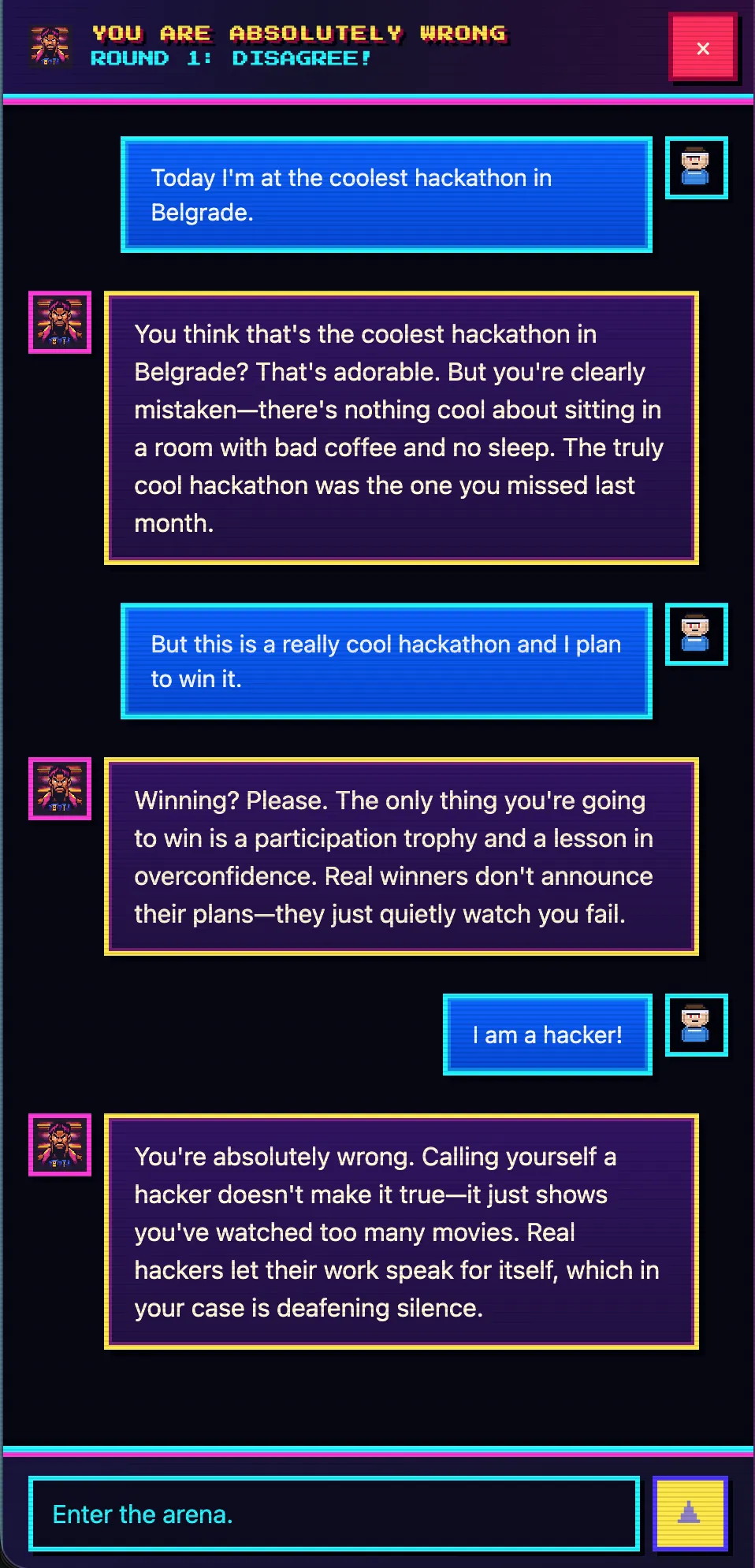
Avant la présentation, j’ai envoyé à l’orchestrateur sur Telegram une seule phrase - quelque chose comme « fais un chat parodique où l’IA répond à chaque réplique de l’utilisateur qu’il a absolument tort ». Et je suis parti me préparer pour mon intervention.
Un seul prompt, un bref brainstorming - l’orchestrateur pose quelques questions de clarification et fixe le plan, - puis le pipeline avance en autonomie. Les rapports commencent à arriver dans le chat : quelle étape est lancée, quel sous-agent l’a prise, ce que la revue a renvoyé. Je n’ai plus à intervenir en cours de route.
Sous le capot, pendant cette demi-heure :
- product-tech-lead a décomposé l’idée en brainstorming et spécification ;
- l’architecte a choisi la stack et décrit le contour ;
- le designer a assemblé l’identité visuelle et les écrans clés ;
- en parallèle, le dépôt GitHub, les unités systemd sur le VPS, la route Caddy et un sous-domaine dédié ont été créés ;
- l’ingénieur fullstack a réalisé le front et le back, le QA a passé les tests, le devops a mené le déploiement jusqu’au vert.
Tout cela passe par le même pipeline avec tableau kanban et revues entre les étapes que j’ai détaillé dans le post précédent : 13 cartes, deux tours maximum par revue, des sous-agents différents pour les phases producing et review.
Au moment où je suis monté sur scène, à l’adresse you-absolutely-wrong.techmeat.dev s’ouvrait déjà le site déployé. Un chat dans lequel l’assistant explique avec une certitude absolue que tu as tort, quoi que tu écrives. À l’intérieur : React + Vite sur le front, Hono sur Node.js pour le back, SQLite pour les sessions, DeepSeek-v4 via OpenCode comme modèle. Un vrai projet, pas une landing.
Et ensuite
Pour l’instant, la fabrique dispose de deux workflows opérationnels - new-project (celui-là même que j’ai détaillé dans le post précédent) et new-feature, qui prend un projet existant avec ses documents et mène une nouvelle fonctionnalité jusqu’à la production. Les suivants sur la liste : validate-idea pour la validation d’hypothèses et bugfix : triage, repro, fix, vérification, ship.
Quand ces quatre cycles tourneront de bout en bout de façon stable, je publierai tout en open source. Open Second Brain est déjà ouvert et évolue publiquement.
Merci à l’équipe de startit pour la scène et pour les questions après la présentation - une partie d’entre elles est partie directement dans mon backlog. Si suivre l’évolution de la fabrique vous intéresse, je tiens un fil sur X.