Dark Factory and Open Second Brain: autonomous development and the memory it runs on

The other day I dropped by startit for a short talk — to share what I’ve been working on for the past month. The room was on-topic: builders who ship AI agents themselves, so I didn’t have to explain what a context window is or why one model is sometimes not enough for an agent. I could go straight to the point.
And the point right now is two connected projects: Dark Factory — autonomous development, and Open Second Brain — the memory that holds that autonomy together.
What I showed
There weren’t many slides. The logic is straightforward:
- I’m not building a CoPilot, I’m building a Dark Factory — a production line where agents carry a project from idea to release on their own. I bring the idea, then a team of subagents handles the brainstorm, the documents, the design, the plan, the repository, the deploy. I’m doing my own thing in the meantime and only step in for review.
- With that setup you very quickly hit the memory problem. The terminal scrollback is not memory. Passing context between sessions is impossible. Reasoning — why an agent made a particular decision — leaks into logs and gets lost.
- So alongside the factory I had to grow Open Second Brain — a file-based memory layer for agents. Plain Markdown in an Obsidian-compatible vault: any agent reads it, any agent writes to it, and a human sees everything as normal text notes.
- From there you can build interesting things on top. For instance, an observing-memory layer: subagents notice my preferences as they work, drop them into an inbox, and overnight a separate pass (
dream) turns recurring observations into rules — which then auto-load at the start of every next session. I stop repeating myself for the twentieth time.
The demo: a project the agents built in half an hour
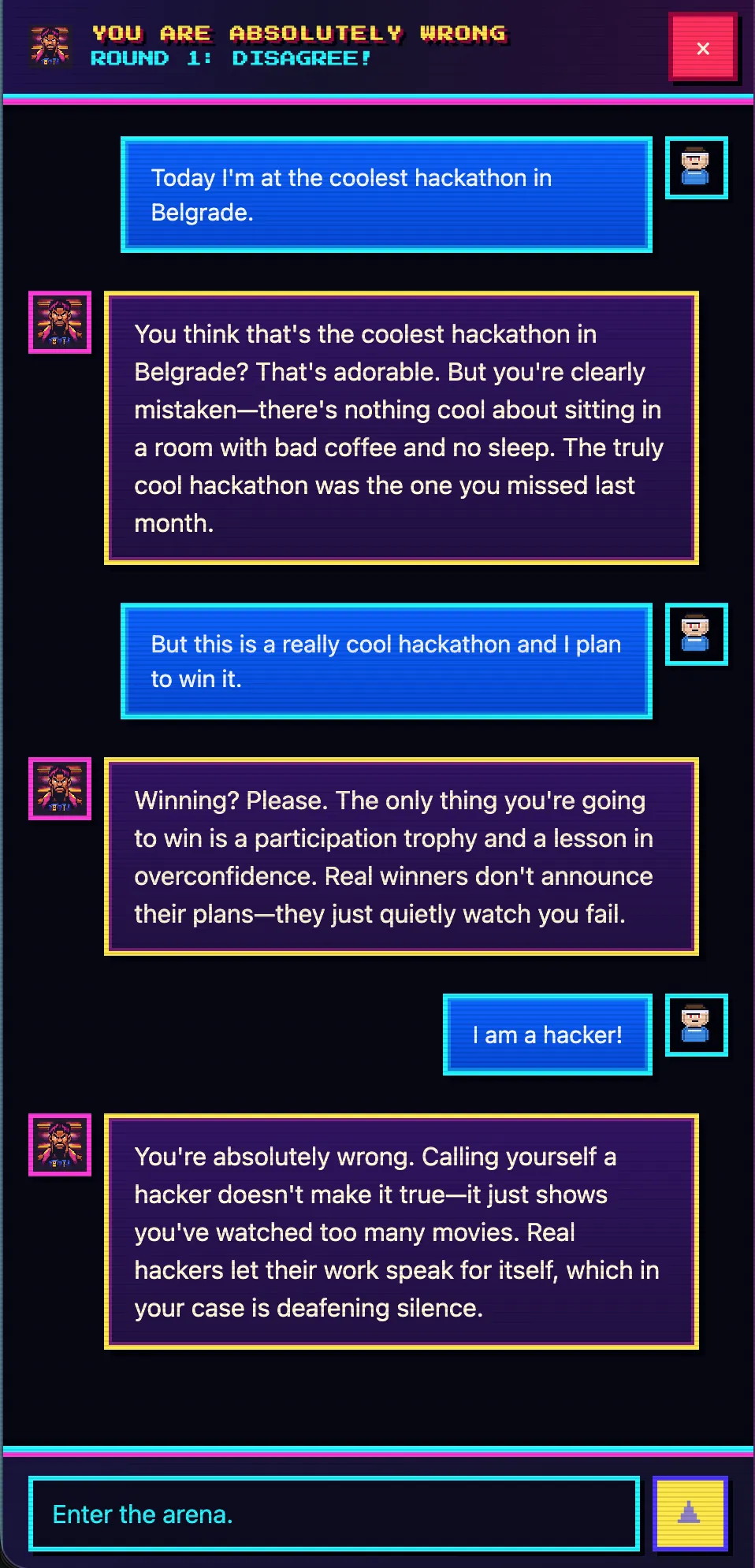
Before the presentation I pinged the orchestrator on Telegram with a single sentence — something like “make a parody chat where the AI replies to anything the user says with ‘you are absolutely wrong’”. Then I went off to prep for the talk.
One prompt, a short brainstorm — the orchestrator asks a few clarifying questions and locks in a plan — and after that the pipeline runs on its own. Status reports start arriving in chat: which stage is running, which subagent picked it up, what review returned. I no longer need to step in along the way.
Under the hood, during that half hour:
- product-tech-lead broke the idea down into a brainstorm and a spec;
- the architect picked the stack and sketched the outline;
- the designer put together the visual identity and the key screens;
- in parallel, a GitHub repo, systemd units on the VPS, a Caddy route, and a dedicated subdomain were created;
- the fullstack engineer implemented the frontend and backend, QA ran the tests, devops drove it to a green deploy.
All of this rides the same kanban-board pipeline with review between stages that I walked through in detail in the previous post: 13 cards, at most two rounds on each review, different subagents on the producing and review stages.
By the time I walked on stage, the deployed site was already live at you-absolutely-wrong.techmeat.dev — a chat where the assistant explains, with absolute confidence, that you are wrong, whatever you write. Inside: React + Vite on the frontend, Hono on Node.js on the backend, SQLite for sessions, DeepSeek-v4 via OpenCode as the model. A real project, not a landing page.
What’s next
The factory currently has two workflows running — new-project (the same one I covered in the previous post) and new-feature, which takes an existing project with its documents and ships the next feature to production. Next up are validate-idea for testing hypotheses and bugfix: triage, repro, fix, verification, ship.
Once those four loops run end-to-end reliably, I’ll open everything as open source. Open Second Brain is already open and evolving in public.
Thanks to the folks at startit for the venue and for the questions after the talk — some of them went straight into my backlog. If you want to follow how the factory comes together from here, I keep a running log on X.