Dark Factory e Open Second Brain: desenvolvimento autônomo e a memória que o sustenta

Outro dia passei no startit com uma palestra curta — para contar o que venho fazendo no último mês. O público era especializado — builders que constroem agentes de IA por conta própria, então não precisei explicar o que é context window nem por que um agente às vezes não se basta com um único modelo. Dava para ir direto ao ponto.
E o ponto, agora, são dois projetos conectados: Dark Factory — desenvolvimento autônomo, e Open Second Brain — a memória sobre a qual essa autonomia se sustenta.
O que mostrei
Foram poucos slides. A lógica é simples:
- Não estou construindo um CoPilot, e sim uma Dark Factory — uma linha de produção em que os agentes levam o projeto da ideia até o release por conta própria. Eu trago a ideia, e a partir daí uma equipe de subagentes faz brainstorming, documentos, design, planejamento, repositório e deploy. Enquanto isso, eu cuido do que preciso e só entro em cena para revisar.
- Com esse arranjo, a gente esbarra muito rápido no problema da memória. O scrollback do terminal não é memória. Não dá para passar contexto entre sessões. O reasoning — o porquê de o agente ter tomado uma decisão específica — vaza para os logs e se perde.
- Por isso, ao lado da fábrica, precisei fazer crescer o Open Second Brain — uma camada de memória em arquivos para os agentes. Markdown puro em um vault compatível com Obsidian: qualquer agente lê, qualquer um escreve, e para o humano tudo aparece como anotações de texto comuns.
- A partir daí, dá para construir coisas interessantes. Por exemplo, uma camada de memória observacional: os subagentes, no decorrer do trabalho, notam minhas preferências, despejam no inbox, e à noite um passo separado (
dream) transforma observações recorrentes em regras, que são carregadas automaticamente no início de cada sessão seguinte. Eu paro de repetir a mesma coisa vinte vezes.
Demonstração: um projeto que os agentes montaram em meia hora
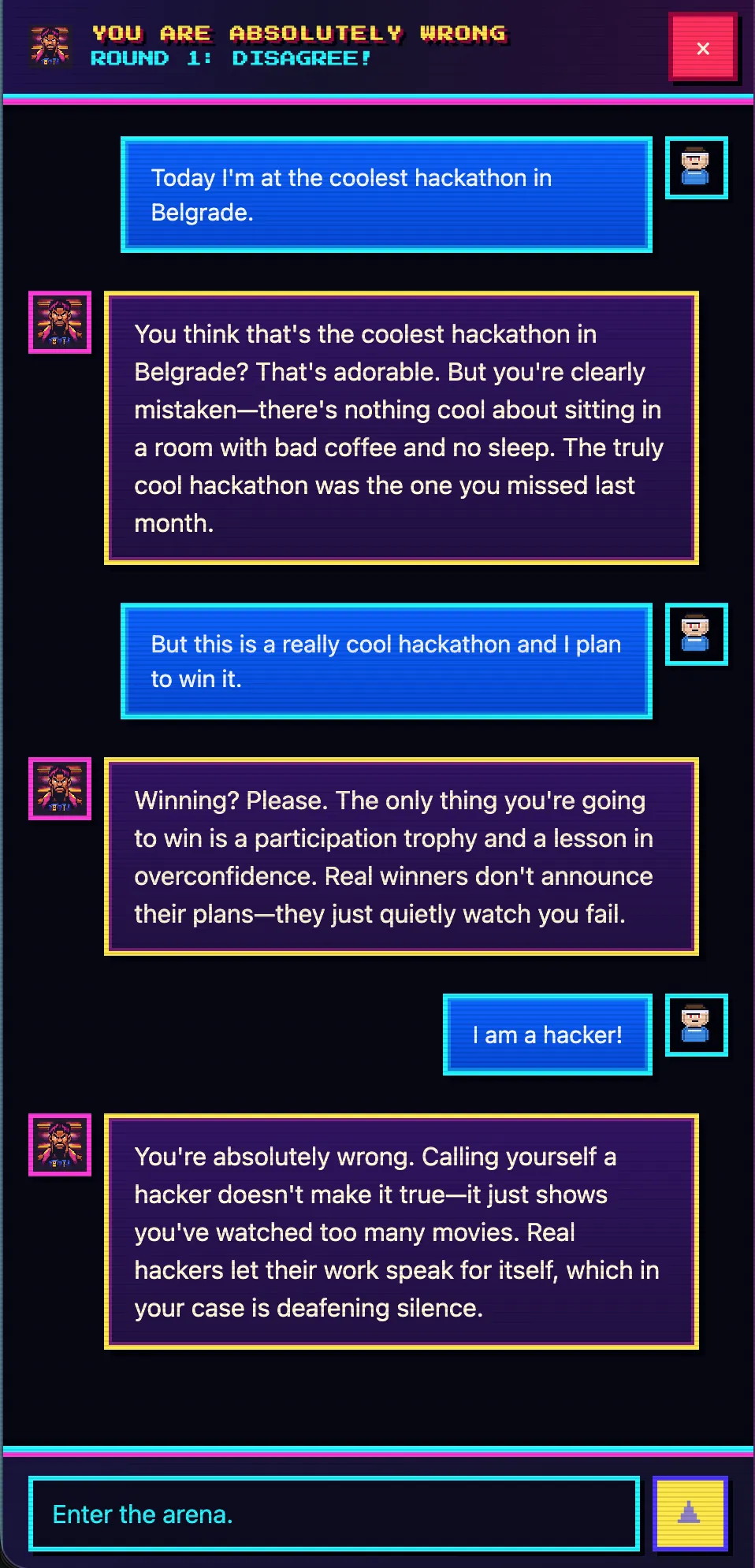
Antes da apresentação, mandei uma frase para o orquestrador no Telegram — algo como “faça um chat paródico em que a IA responde a qualquer fala do usuário dizendo que ele está absolutamente errado”. E fui me preparar para subir ao palco.
Um prompt, um brainstorming curto — o orquestrador faz algumas perguntas de esclarecimento e fixa o plano — e, daí em diante, o pipeline roda sozinho. No chat começam a chegar relatórios do que está acontecendo: qual etapa foi iniciada, qual subagente assumiu, o que a revisão retornou. Não preciso mais intervir no meio do caminho.
Por baixo dos panos, nessa meia hora:
- o product-tech-lead decompôs a ideia em brainstorming e especificação;
- o arquiteto escolheu a stack e descreveu o contorno do sistema;
- o designer montou a identidade visual e as telas principais;
- em paralelo, foram criados o repositório no GitHub, as units do systemd no VPS, a rota no Caddy e um subdomínio dedicado;
- o engenheiro fullstack implementou frontend e backend, o QA rodou os testes, e o devops levou o deploy até o verde.
Tudo isso passa pelo mesmo pipeline de quadro kanban com revisão entre etapas que detalhei no post anterior: 13 cartões, no máximo duas voltas em cada revisão, subagentes diferentes nas etapas de produção e de revisão.
Quando subi ao palco, no endereço you-absolutely-wrong.techmeat.dev já abria o site no ar. Um chat em que o assistente, com convicção absoluta, explica que você está errado, escreva o que escrever. Por dentro: React + Vite no frontend, Hono em Node.js no backend, SQLite para as sessões, DeepSeek-v4 via OpenCode como modelo. Um projeto completo, não uma landing page.
O que vem a seguir
Hoje, a fábrica opera com dois workflows — new-project (o mesmo que detalhei no post anterior) e new-feature, que pega um projeto já existente, com sua documentação, e leva mais uma feature até produção. Os próximos da fila são validate-idea, para validar hipóteses, e bugfix: triagem, repro, fix, verificação, ship.
Quando esses quatro ciclos rodarem de ponta a ponta de forma consistente, vou abrir tudo em open source. O Open Second Brain já está aberto e evolui publicamente.
Obrigado ao pessoal do startit pelo espaço e pelas perguntas depois da palestra — algumas delas foram direto para o meu backlog. Se você quiser acompanhar como a fábrica vai se montando daqui em diante, eu vou contando a história no X.