Dark Factory и Open Second Brain: автономная разработка и память, на которой она держится

На днях зашёл в startit с коротким докладом - рассказать, чем я занимаюсь последний месяц. Народ в зале был профильный - билдеры, которые сами строят AI-агентов, так что не нужно было объяснять, что такое context window и почему агенту бывает мало одной модели. Можно было сразу переходить к сути.
А суть у меня сейчас в двух связанных проектах: Dark Factory - автономная разработка, и Open Second Brain - память, на которой эта автономия держится.
Что я показывал
Слайдов было немного. Логика простая:
- Я строю не CoPilot, а Dark Factory - производство, где агенты сами доводят проект от идеи до релиза. Я приношу идею, дальше команда субагентов делает брейншторм, документы, дизайн, план, репозиторий, деплой. Я в это время занимаюсь своим делом и подключаюсь только на ревью.
- Очень быстро при такой постановке упираешься в проблему памяти. Скроллбэк терминала - это не память. Передать контекст между сессиями невозможно. Reasoning - почему агент принял конкретное решение - утекает в логи и теряется.
- Поэтому рядом с фабрикой пришлось вырастить Open Second Brain - файловый слой памяти для агентов. Plain Markdown в Obsidian-совместимом vault: любой агент читает, любой пишет, всё видно человеку как обычные текстовые заметки.
- Дальше уже можно строить интересное. Например, слой наблюдательной памяти: субагенты по ходу работы подмечают мои предпочтения, складывают в инбокс, ночью отдельный проход (
dream) превращает повторяющиеся наблюдения в правила, и эти правила автоматически подгружаются в начало каждой следующей сессии. Я перестаю повторять одно и то же по двадцать раз.
Демонстрация: проект, который агенты собрали за полчаса
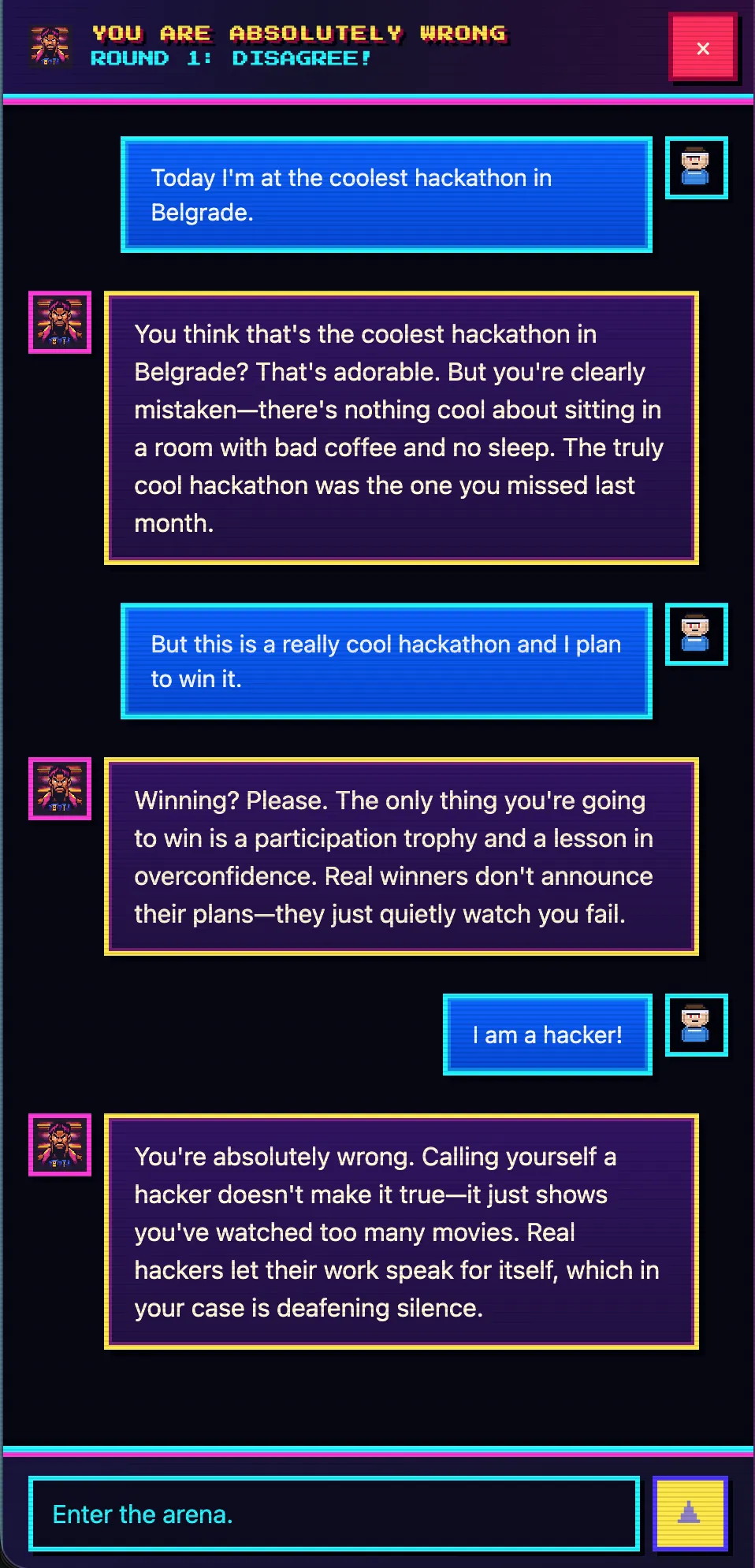
Перед презентацией я кинул в Telegram оркестратору одну фразу - примерно «сделай пародийный чат, где AI на любую реплику пользователя отвечает, что он абсолютно неправ». И пошёл готовиться к выступлению.
Один промпт, короткий брейншторм - оркестратор задаёт несколько уточняющих вопросов и фиксирует план, - дальше пайплайн идёт автономно. В чат начинают сыпаться отчёты о происходящем: какая стадия запущена, кто из субагентов её взял, что вернуло ревью. Вмешиваться по ходу мне больше не нужно.
Под капотом за эти полчаса:
- product-tech-lead разложил идею на брейншторм и спецификацию;
- архитектор выбрал стек и описал контур;
- дизайнер собрал визуальную идентику и ключевые экраны;
- параллельно создались GitHub-репозиторий, systemd-юниты на VPS, Caddy-роут и отдельный поддомен;
- fullstack-инженер реализовал фронт и бэк, QA прогнал тесты, devops довёл до зелёного деплоя.
Всё это идёт через тот же конвейер канбан-доски с ревью между этапами, что я подробно разбирал в прошлом посте: 13 карточек, два круга максимум на каждое ревью, разные субагенты на producing и review-стадиях.
К моменту выхода на сцену по адресу you-absolutely-wrong.techmeat.dev уже открывался задеплоенный сайт. Чат, в котором ассистент с абсолютной уверенностью объясняет, что ты не прав, что бы ты ни написал. Внутри React + Vite на фронте, Hono на Node.js на бэке, SQLite для сессий, DeepSeek-v4 через OpenCode в качестве модели. Полноценный проект, не лендинг.
Что дальше
Сейчас у фабрики работают два workflow - new-project (тот самый, который я подробно разбирал в прошлом посте) и new-feature, который берёт уже существующий проект с его документами и доводит очередную фичу до production. Следующие на очереди - validate-idea для проверки гипотез и bugfix: триаж, репро, фикс, верификация, ship.
Когда эти четыре цикла начнут устойчиво идти от начала до конца, я открою всё в опенсорс. Open Second Brain уже открыт и развивается публично.
Спасибо ребятам из startit за площадку и за вопросы после доклада - часть из них уехала прямо в мой бэклог. Если интересно следить за тем, как фабрика собирается дальше, я веду историю в X.