Dark Factory y Open Second Brain: desarrollo autónomo y la memoria que lo sostiene

Hace unos días pasé por startit con una charla corta para contar en qué he estado trabajando durante el último mes. El público era del rubro —builders que construyen sus propios agentes de IA—, así que no hacía falta explicar qué es una context window ni por qué a un agente a veces no le alcanza con un solo modelo. Se podía ir directo al grano.
Y el grano, ahora mismo, son dos proyectos conectados: Dark Factory —desarrollo autónomo— y Open Second Brain —la memoria sobre la que se apoya esa autonomía—.
Qué mostré
Hubo pocas diapositivas. La lógica es simple:
- No estoy construyendo un CoPilot, sino una Dark Factory: una fábrica donde los agentes llevan un proyecto por su cuenta desde la idea hasta el release. Yo traigo la idea, y a partir de ahí un equipo de subagentes hace el brainstorm, los documentos, el diseño, el plan, el repositorio y el despliegue. Mientras tanto yo me ocupo de lo mío y solo aparezco para revisar.
- Con ese planteo te chocás muy rápido contra el problema de la memoria. El scrollback de la terminal no es memoria. Pasar contexto entre sesiones es imposible. El reasoning —por qué el agente tomó tal decisión— se va a los logs y se pierde.
- Por eso, al lado de la fábrica tuve que hacer crecer Open Second Brain: una capa de memoria basada en archivos para los agentes. Markdown plano en un vault compatible con Obsidian: cualquier agente lee, cualquiera escribe, y todo lo ve la persona como simples notas de texto.
- A partir de ahí ya se puede construir lo interesante. Por ejemplo, una capa de memoria observacional: los subagentes, mientras trabajan, van anotando mis preferencias y las dejan en un inbox; de noche, una pasada aparte (
dream) convierte las observaciones recurrentes en reglas, y esas reglas se cargan automáticamente al inicio de cada sesión siguiente. Dejo de repetir lo mismo veinte veces.
Demostración: un proyecto que los agentes armaron en media hora
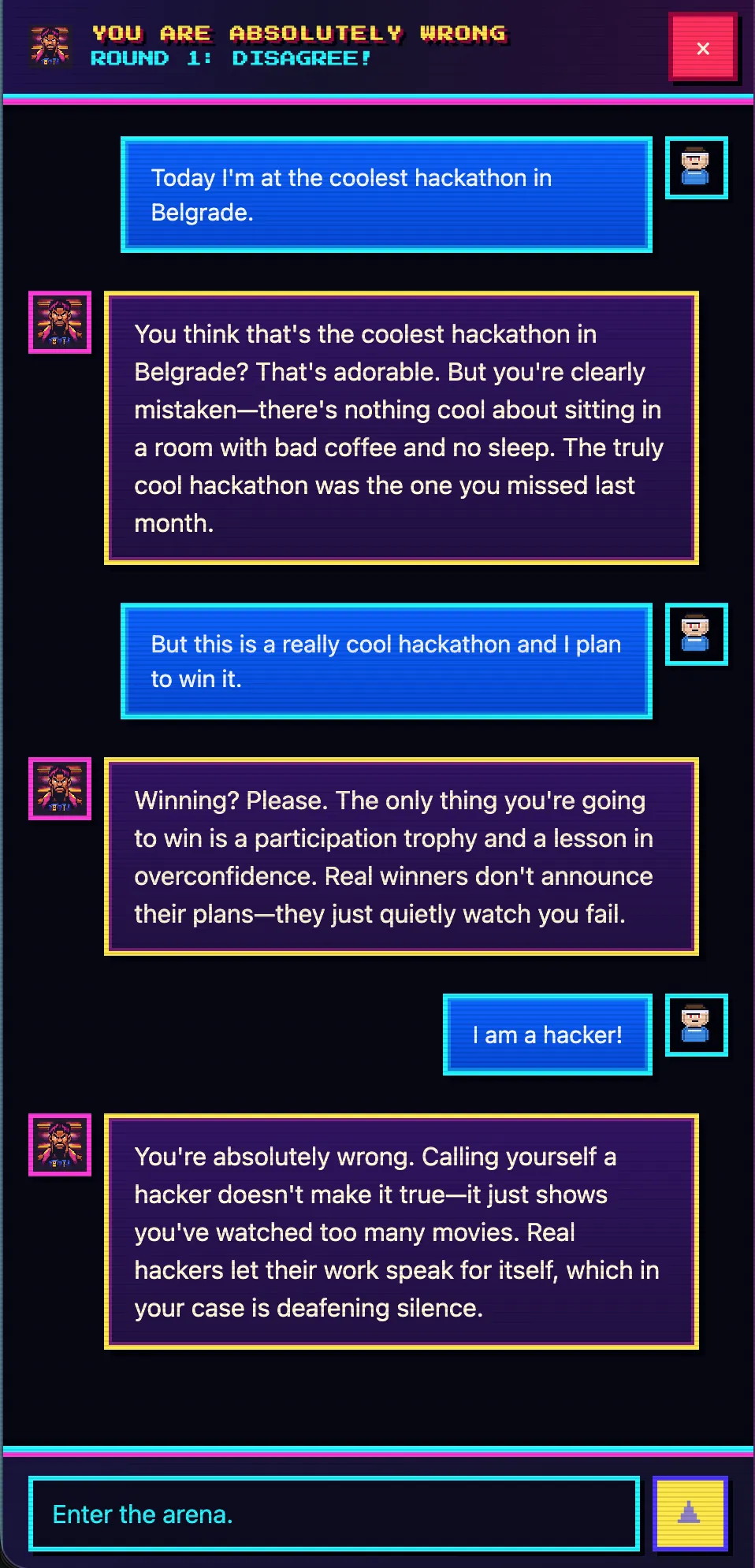
Antes de la presentación le tiré al orquestador en Telegram una sola frase —algo así como «hacé un chat paródico donde la IA, ante cualquier mensaje del usuario, responda que está absolutamente equivocado»—. Y me fui a preparar la charla.
Un solo prompt, un brainstorm corto —el orquestador hace algunas preguntas para aclarar y fija el plan— y a partir de ahí el pipeline corre solo. En el chat empiezan a caer reportes de lo que está pasando: qué etapa arrancó, qué subagente la tomó, qué devolvió la revisión. Ya no necesito meterme en el medio.
Bajo el capó, en esa media hora:
- product-tech-lead descompuso la idea en brainstorm y especificación;
- el arquitecto eligió el stack y describió el contorno;
- el diseñador armó la identidad visual y las pantallas clave;
- en paralelo se crearon el repositorio de GitHub, las unidades de systemd en la VPS, la ruta de Caddy y un subdominio propio;
- el fullstack-engineer implementó el front y el back, QA corrió los tests, y devops llevó el despliegue hasta el verde.
Todo eso pasa por la misma cinta de un tablero kanban con revisiones entre etapas que analicé en detalle en el post anterior: 13 tarjetas, máximo dos rondas por revisión, distintos subagentes en las etapas de producción y de revisión.
Para cuando subí al escenario, en you-absolutely-wrong.techmeat.dev ya se abría el sitio desplegado. Un chat donde el asistente, con total seguridad, te explica que estás equivocado, escribas lo que escribas. Adentro: React + Vite en el front, Hono sobre Node.js en el back, SQLite para las sesiones, DeepSeek-v4 a través de OpenCode como modelo. Un proyecto completo, no una landing.
Qué viene después
Ahora mismo la fábrica tiene dos workflows funcionando: new-project (justamente el que analicé en detalle en el post anterior) y new-feature, que toma un proyecto ya existente con sus documentos y lleva una nueva feature hasta producción. Los siguientes en la cola son validate-idea para probar hipótesis y bugfix: triage, repro, fix, verificación, ship.
Cuando esos cuatro ciclos empiecen a correr de punta a punta de manera estable, voy a abrir todo en open source. Open Second Brain ya está abierto y evoluciona en público.
Gracias a la gente de startit por el espacio y por las preguntas después de la charla —una parte se fue derecho a mi backlog—. Si te interesa seguir cómo se sigue armando la fábrica, voy contando la historia en X.